
 Ein gescanntes PDF-Dokument ist eine digitale Datei, die ein Bild eines mit einem Scanner gescannten physischen Dokuments enthält. Der Scanner erfasst den Text und die Bilder auf dem physischen Dokument, wandelt sie in ein digitales Format um und speichert sie dann als PDF-Datei. Gescannte PDF-Dokumente können jede Art von gedrucktem Material enthalten, einschließlich Bücher, Berichte, Rechnungen und andere Dokumente. Im Gegensatz zu bearbeitbaren PDF-Dokumenten können gescannte PDF-Dokumente in der Regel nicht durchsucht oder bearbeitet werden, ohne dass Software zur optischen Zeichenerkennung (OCR) verwendet wird.
Ein gescanntes PDF-Dokument ist eine digitale Datei, die ein Bild eines mit einem Scanner gescannten physischen Dokuments enthält. Der Scanner erfasst den Text und die Bilder auf dem physischen Dokument, wandelt sie in ein digitales Format um und speichert sie dann als PDF-Datei. Gescannte PDF-Dokumente können jede Art von gedrucktem Material enthalten, einschließlich Bücher, Berichte, Rechnungen und andere Dokumente. Im Gegensatz zu bearbeitbaren PDF-Dokumenten können gescannte PDF-Dokumente in der Regel nicht durchsucht oder bearbeitet werden, ohne dass Software zur optischen Zeichenerkennung (OCR) verwendet wird.
Vorteile der durchsuchbaren PDF-Datei
Zu den Vorteilen durchsuchbarer PDF-Dokumente gehören:
- Gesteigerte produktivität: Die Suche nach bestimmten Informationen in einem durchsuchbaren PDF-Dokument ist viel schneller und effizienter als das manuelle Durchsuchen von Textseiten.
- Verbesserte Zugänglichkeit: Screenreader können durchsuchbare PDF-Dokumente laut vorlesen, sodass sie für sehbehinderte Personen zugänglich sind.
- Einfachere Zusammenarbeit: Die Zusammenarbeit an Dokumenten wird einfacher, wenn der Text durchsuchbar ist. Teammitglieder können schnell die notwendigen Informationen finden und extrahieren, um ihre Arbeit abzuschließen.
- Reduzierter Speicherplatz: Durchsuchbare PDF-Dokumente können komprimiert werden, ohne ihre Durchsuchbarkeit zu verlieren, wodurch sie weniger Speicherplatz beanspruchen.
Die OCR-Technologie (Optical Character Recognition) hilft bei der Generierung durchsuchbarer PDF-Dokumente. Es ist ein Softwaretool, das große Mengen an Dokumenten digitalisiert, physische Aufzeichnungen in durchsuchbare elektronische Dateien umwandelt und die Genauigkeit der Dateneingabe verbessert. OCR-Software kann eigenständig, in einen Scanner eingebettet oder in eine Dokumentenverwaltungssoftware integriert werden. Die OCR-Genauigkeit kann jedoch durch Dokumentqualität, Schriftart und Sprache beeinträchtigt werden, daher ist die Auswahl hochwertiger OCR-Software und die Optimierung des Scanvorgangs für die besten Ergebnisse entscheidend.
Was ist OCR?
OCR, bekannt als optische Zeichenerkennung, ist eine Technologie, die die Erkennung von gedrucktem oder handschriftlichem Text in einem Bild ermöglicht und diesen Text dann in maschinenlesbaren Text umwandelt.
Die vier Haupttypen von OCR sind:
- Optical Character Recognition, oder OCR, ist eine Technologie, die verwendet wird, um gedruckten Text in einem Bild zu erkennen und ihn in maschinenlesbaren Text umzuwandeln. Die OCR-Technologie wird häufig zum Digitalisieren von gedruckten Dokumenten wie Büchern, Zeitschriften und juristischen Dokumenten verwendet.
- OWR, oder Optical Word Recognition, ist eine der OCR ähnliche Technologie, die jedoch speziell entwickelt wurde, um ganze Wörter in einem Bild zu erkennen. Diese Technologie wird häufig in Handschrifterkennungsanwendungen verwendet, bei denen es wesentlich ist, ganze Wörter statt einzelner Zeichen zu erkennen.
- OMR oder Optical Mark Recognition ist eine Technologie zur Erkennung bestimmter Markierungen auf einem Papierformular, wie z. B. Kontrollkästchen oder Blasen. Die OMR-Technologie wird häufig in standardisierten Tests, Umfragen und anderen Anwendungen verwendet, bei denen Daten aus Papierformularen erfasst werden müssen.
- ICR, oder Intelligent Character Recognition, ist eine Technologie, die handschriftlichen Text in einem Bild erkennt. Die ICR-Technologie ist komplexer als OCR oder OWR, da sie die Identifizierung einzelner Zeichen und den Abgleich dieser Zeichen mit einer Datenbank bekannter Zeichen erfordert.
Beim Vergleich dieser Technologien ist es wichtig, ihre Stärken und Schwächen zu berücksichtigen.
- OCR ist sehr genau für die Erkennung von gedrucktem Text, kann jedoch Probleme mit Handschrift oder schlecht gedrucktem Text haben.
- OWR ist explizit für die Handschrifterkennung konzipiert und kann für diese Anwendung genauer sein.
- OMR ist sehr genau beim Erkennen bestimmter Markierungen auf einem Papierformular, kann jedoch keinen Text erkennen.
- ICR ist am komplexesten und kann ein breiteres Spektrum an Handschriften verarbeiten, erfordert jedoch möglicherweise eine umfassende Schulung und ist für einige Anwendungen möglicherweise nicht genau genug.
Letztendlich hängt die Wahl der Technologie von der konkreten Anwendung und der Art der zu erkennenden Texte oder Symbole ab.
Vergleich beliebter OCR-Software, die 2023 verfügbar ist
Wie bereits erwähnt, wird die OCR-Technologie hauptsächlich zum automatischen Extrahieren von Text aus gescannten PDFs und Bildern verwendet. Zu diesem Zweck stehen zahlreiche Tools zur Verfügung, und hier geben wir eine kurze Einführung in die beliebteste OCR-Software im Jahr 2023:
- AcePDF
- Tesserakt OCR
- ABBYY Finereader
- Google Cloud-Vision
- Amazontext
Alle diese Tools verfügen über unterschiedliche Funktionen, und wir haben ihre Stärken und Schwächen bewertet, um es Ihnen leicht zu machen, das beste OCR-Tool auszuwählen, das Ihren Zwecken am besten entspricht. In unserem Vergleich haben wir festgestellt, dass AcePDF einfach zu bedienen ist und eine Reihe von OCR-bezogenen Funktionen bietet, die die Aufgabe der PDF-Texterkennung für Sie zum Kinderspiel machen. Es hat keine Probleme mit den gut gescannten Dokumenten und hat sogar den Text im mit dem Smartphone erfassten Dokument ähnlich gut erkannt.
OCR ein gescanntes PDF-Dokument
Die meisten im Internet verbreiteten PDFs enthalten Text, und viele beliebte Desktop- und Mobilprogramme sowie Scanner-Softwarepakete verfügen über eine integrierte OCR-Technologie. Dennoch gibt es immer noch Fälle, in denen das Quelldokument oder -bild erhebliche Mengen an nicht eingebettetem Text enthält kann nicht mechanisch herausgezogen werden.
In diesem Szenario kann OCR mithilfe einer Pipeline aus kostenloser und Open-Source-Software automatisch durchgeführt werden. Dies ist besonders hilfreich, wenn Sie mit einem umfangreichen Korpus von Dokumenten arbeiten, deren gesamter Text indiziert werden muss, oder wenn Sie Dokumente oder Bilder in eine Webanwendung aufnehmen, die Text extrahieren muss.
Hier ist eine Schritt-für-Schritt-Anleitung zum OCR eines gescannten PDF-Dokuments:
- Wählen Sie eine OCR-Software: Auf dem Markt sind mehrere OCR-Programme erhältlich. Sie können eine davon auswählen, z. B. AcePDF oder eine andere, mit der Sie vertraut sind.
- Öffnen Sie das gescannte PDF-Dokument: Öffnen Sie das PDF-Dokument, das Sie mit OCR bearbeiten möchten, in Ihrer OCR-Software.
- Wählen Sie die OCR-Funktion: Starten Sie den OCR-Vorgang, indem Sie das OCR-Tool in Ihrer OCR-Software auswählen. Der Speicherort des OCR-Tools kann je nach verwendeter Software variieren.
- OCR-Einstellungen auswählen: Wählen Sie die Sprache des Dokuments, für das Sie OCR verwenden möchten. Möglicherweise haben Sie auch die Möglichkeit, die OCR-Genauigkeitsstufe auszuwählen, die sich auf die Verarbeitungszeit und die Ausgabequalität auswirken kann.
- Starten Sie den OCR-Vorgang: Nachdem Sie die OCR-Einstellungen ausgewählt haben, starten Sie den OCR-Vorgang, indem Sie auf die Schaltfläche „OCR“ klicken. Abhängig von der Größe des Dokuments und der von Ihnen ausgewählten Genauigkeitsstufe kann dies einige Zeit dauern.
- OCR-Ausgabe überprüfen: Überprüfen Sie nach Abschluss des OCR-Vorgangs die OCR-Ausgabe, um sicherzustellen, dass der Text korrekt erkannt wird. Suchen Sie nach Fehlern, Rechtschreibfehlern oder Formatierungsproblemen.
- Speichern Sie die OCR-Ausgabe: Wenn Sie mit der OCR-Ausgabe zufrieden sind, speichern Sie das Dokument mit der OCR-Ausgabe als neue PDF-Datei. Möglicherweise können Sie das Dokument auch in anderen Formaten wie Microsoft Word oder Nur-Text speichern.
- Bearbeiten Sie die OCR-Ausgabe (optional): Wenn die OCR-Ausgabe Fehler enthält, können Sie den Text in Ihrer OCR-Software bearbeiten oder den Text in ein Textverarbeitungsprogramm exportieren, um die erforderlichen Änderungen vorzunehmen.
Mit diesen Schritten können Sie ein gescanntes PDF-Dokument per OCR erkennen und in ein durchsuchbares und bearbeitbares digitales Format konvertieren.
Beste OCR-Software
Wenn Sie neu in der optischen Zeichenerkennung (OCR) sind, ist AcePDF das einzige Tool, das Sie brauchen. Die Durchführung von OCR, um gescannte PDFs durchsuchbar zu machen, ist nur eine der vielen Funktionen, bei denen AcePDF Ihnen helfen kann. Als robuster PDF-Editor und -Konverter verfügt es über viele einzigartige Tools, die Sie bei der Verwaltung Ihrer PDF-Workflows unterstützen und Ihnen letztendlich dabei helfen, produktiver bei der Arbeit zu sein. Einige dieser erstaunlichen Funktionen sind wie folgt:
- Anmerkungen und Markup-Funktionen sind in diesem PDF-Editor reichlich vorhanden, was das Kommentieren von PDF-Dokumenten mit Hervorhebungen, Unterstreichungen, Legenden, Pfeilen und vielem mehr ermöglicht.
- Konvertieren Sie PDFs mühelos in bearbeitbare Formate wie Word, Excel oder PowerPoint mit dem integrierten Konverter dieses PDF-Editors.
- Kopf- und Fußzeilen verbessern die Lesbarkeit des PDF-Dokuments als Ganzes.
Häufige OCR-Probleme und Lösungen
Die OCR-Technologie kann beim Erkennen von Text in Bildern hilfreich sein, aber während des OCR-Prozesses können mehrere allgemeine Probleme auftreten. Hier sind einige der häufigsten OCR-Probleme und wie AcePDF helfen kann, sie zu lösen:
- Schlechte Bildqualität: Wenn das Bild, das mit OCR bearbeitet wird, von schlechter Qualität ist, erkennt die OCR-Software den Text möglicherweise nicht genau. AcePDF verwendet fortschrittliche Bildverarbeitungsalgorithmen, um die Bildqualität zu verbessern und die OCR-Genauigkeit zu verbessern.
- Gemischte Sprachen: Wenn das Bild Text in mehreren Sprachen enthält, hat die OCR-Software möglicherweise Schwierigkeiten, den Text zu erkennen. AcePDF unterstützt OCR für über 20 Sprachen, wodurch es einfach ist, Text in gemischten Sprachen genau zu erkennen.
- Komplexe Layouts: Die OCR-Software hat möglicherweise Schwierigkeiten, den Text genau zu erkennen, wenn das Bild komplexe Layouts enthält, z. B. mehrere Spalten oder Tabellen. Die fortschrittlichen OCR-Algorithmen von AcePDF wurden entwickelt, um Text in komplexen Layouts genau zu identifizieren, wodurch es einfach ist, Daten aus solchen Dokumenten zu extrahieren.
- Große Dokumente: Wenn das Bild, das mit OCR bearbeitet wird, groß ist, kann es lange dauern, bis der OCR-Vorgang abgeschlossen ist. AcePDF verwendet fortschrittliche Parallelverarbeitungsalgorithmen, um große Dokumente schnell und effizient mit OCR zu versehen.
Machen Sie gescannte PDF-Dateien durchsuchbar
Ein durchsuchbares PDF ist ein Dokument, das es dem Benutzer ermöglicht, nach bestimmtem Text oder Schlüsselwörtern innerhalb des Dokuments zu suchen.
AcePDF kann verwendet werden, um gescannte PDF-Dateien durchsuchbar zu machen; hier ist wie:
Schritt 1 Installieren Sie AcePDF und starten Sie es
Einführung AcePDF und laden Sie die gescannte PDF-Datei, die Sie durchsuchbar machen möchten. Sobald das gescannte PDF-Dokument in AcePDF geöffnet ist, gehen Sie zum Hauptmenü und wählen Sie das OCR-Tool. In den meisten Fällen finden Sie die OCR-Funktion im Abschnitt „Tools“ auf der linken Seite des Programms.Probieren Sie es kostenlos aus
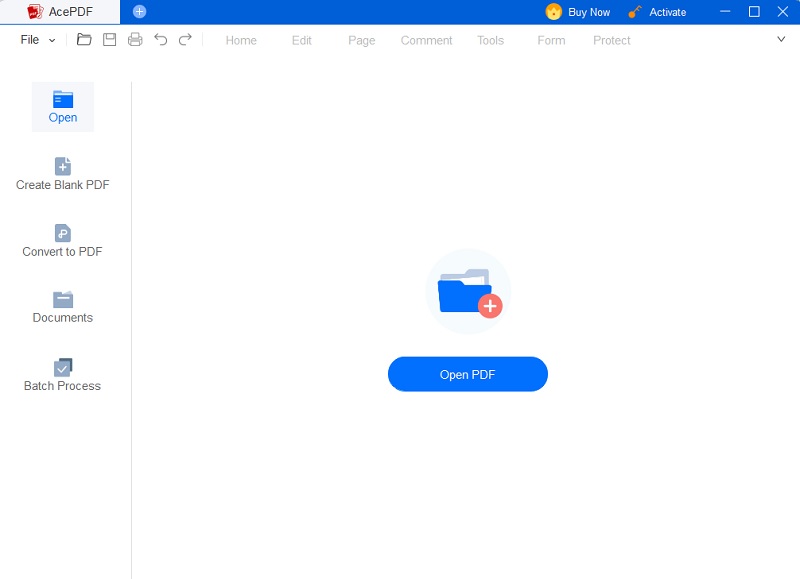
Schritt 2 Wählen Sie im Dialogfeld „OCR-Tool“ die Option „OCR-Sprache und -Einstellungen“.
Wählen Sie OCR-Optionen wie Seitenbereich und Ausgabeformat. Wählen Sie die Sprache des gescannten Dokuments so aus, dass sie mit der Sprache übereinstimmt, die von der optischen Zeichenerkennung (OCR) von AcePDF unterstützt wird.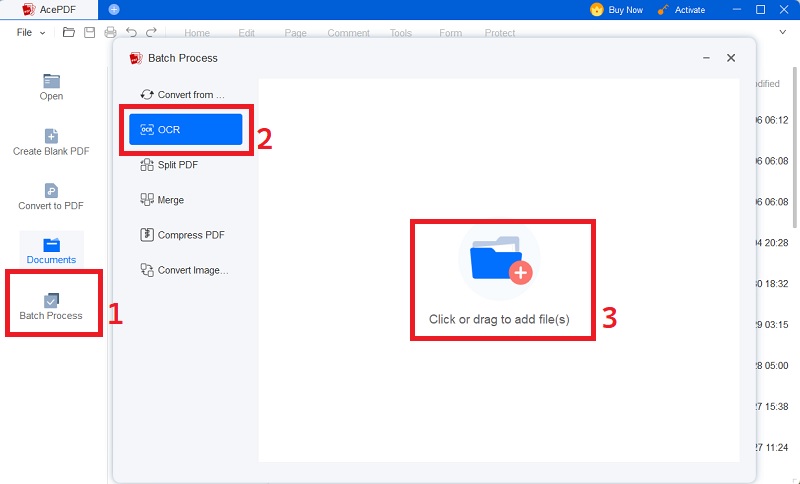
Schritt 3 Starten Sie den OCR-Prozess
Um den OCR-Vorgang zu starten, klicken Sie auf die Schaltfläche „OK“. Danach untersucht AcePDF die Datei und bestimmt, wie der Text aus dem Bild gezogen werden kann. Überprüfen Sie nach Abschluss der OCR die Ausgabe, um sicherzustellen, dass der Text korrekt erkannt wurde. Stellen Sie sicher, dass es frei von Tippfehlern, Grammatikfehlern und schlechter Präsentation ist. Sie können alle Fehler im Text korrigieren, indem Sie ihn in AcePDF bearbeiten.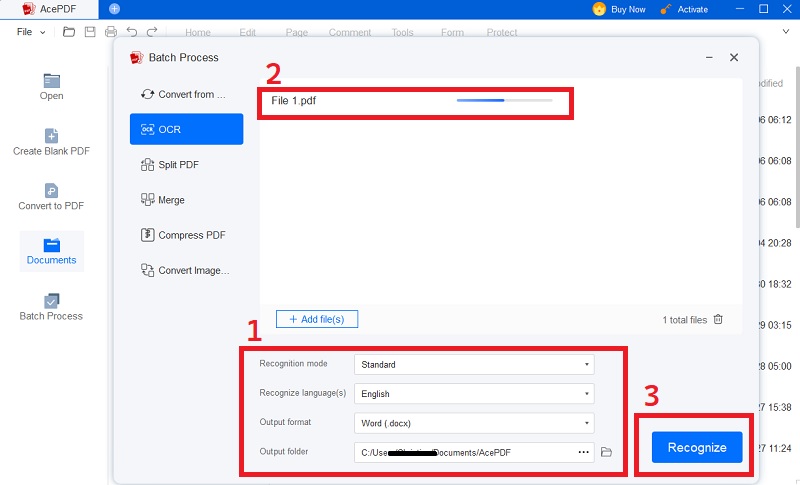
Schritt 4 Speicher die Datei
Speichern der durchsuchbaren PDF-Datei Wenn Sie die gewünschten Ergebnisse erzielt haben, speichern Sie das Dokument als durchsuchbare PDF-Datei.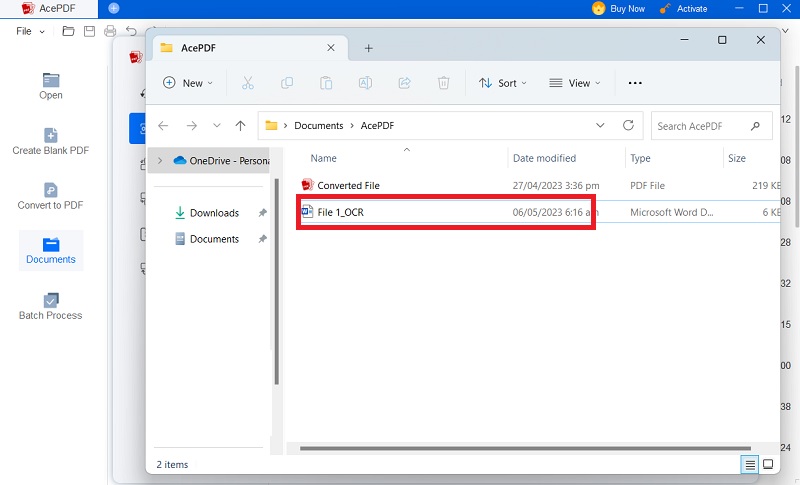
Tipps zum Durchsuchen gescannter PDFs
Es wäre nicht falsch zu sagen, dass PDF derzeit eines der am häufigsten verwendeten Dokumentenformate ist. Manchmal müssen Sie möglicherweise die Texterkennung ausführen, damit der Inhalt auf dieser Seite durchsuchbar und auswählbar ist. Die manuelle Suche nach einem bestimmten Satz oder Wort in einem PDF mit Hunderten von Seiten kann jedoch eine Herausforderung darstellen. Wenn Sie einer dieser Tausenden von Benutzern sind, die häufig PDFs verwenden, dann helfen wir Ihnen hier, zu wissen, wie Sie gescannte PDF-Dokumente durchsuchen können, und diskutieren einige Tipps zum Erstellen gescannter PDFs, die durchsuchbar sind.
Wie suche ich Text in einem gescannten PDF-Dokument?
In diesem Abschnitt finden Sie die Schritte, die Sie ausführen können, um nach einem gescannten PDF zu suchen:
- Zunächst müssen Sie das gescannte PDF in ein bearbeitbares Format konvertieren, z. B. ein Word-Dokument. Zu diesem Zweck können Sie einen PDF-Konverter wie AcePDF verwenden.
- Laden Sie das Dokument in diesem bearbeitbaren Textformat herunter, und dann können Sie die Seiten bearbeiten, anpassen und die Sprache ändern, wenn Sie möchten.
- Im letzten Schritt können Sie nun gezielt nach Ihrem Text suchen. Sie können einfach die Tasten „Strg + F“ drücken und das Wort oder den Ausdruck, nach dem Sie suchen, in die Suchleiste eingeben.
Best Practices, um gescannte PDF-Dokumente durchsuchbar zu machen
Nachdem wir besprochen haben, wie Sie in einem gescannten PDF-Dokument nach Text suchen, stellen wir Ihnen hier einige bewährte Verfahren vor, die Ihnen helfen, die Durchsuchbarkeit und die Vorteile der Verwendung von PDF-Dokumenten zu maximieren.
- Stellen Sie immer sicher, dass Sie die richtige Auflösung erhalten, wenn Sie Bilder in PDF scannen. Da die OCR-Qualität auch unter einer niedrigeren Scanauflösung leiden kann, wird empfohlen, mit 300 dpi (dots per inch) zu scannen.
- Sie sollten sich für Graustufen gegenüber Schwarzweiß entscheiden, da dies dazu beiträgt, mehr Details beizubehalten. Falls Ihr Dokument farbige Bilder oder Diagramme enthält, sollten Sie darauf achten, es im Farbmodus zu scannen.
- Nicht alle OCR-Programme sind gleich, und die Qualität der OCR, um gescannte PDFs durchsuchbar zu machen, hängt von den Einstellungen und Funktionen ab, die von der Software angeboten werden. Daher ist es notwendig, die richtige Software zu erwerben, die OCR in besserer Qualität liefern kann.
- Eine zu hohe oder niedrige Helligkeit kann die Genauigkeit und Durchsuchbarkeit von PDF-Dokumenten beeinträchtigen. Daher wäre eine mittlere Helligkeit von 50 % für die meisten Scans eine sichere Option.
- Normalerweise haben Scanner viele Einstellungen, die helfen können, die Scanqualität und letztendlich die Durchsuchbarkeit zu verbessern. Beispielsweise können „Hintergrundentfernung“ und „Randschattenentfernung“ die Lesbarkeit der Dokumente verbessern. Sie beeinträchtigen jedoch manchmal die OCR-Genauigkeit. Sie sollten also einige Tests durchführen und beobachten, welche Einstellungen dazu beitragen können, Ihre Dokumente durchsuchbar zu machen.
Häufig gestellte Fragen
A. Haben alle PDF-Dateien die gleiche Struktur?
- Absolut nicht! Es gibt viele verschiedene Möglichkeiten, ein PDF zu erstellen. PDFs, die elektronisch und aus gescannten Papierdokumenten generiert wurden, sind die beiden am weitesten verbreiteten Arten, denen Sie begegnen werden. Dies erzeugt ein "natives" PDF bzw. gescannte PDFs. Die PDF-Interaktivität hängt davon ab, wie das Dokument ursprünglich erstellt wurde.

B. Können Sie natives PDF erklären?
- „Native“ PDFs werden digital aus einer anderen digitalen Quelle entwickelt. Ein natives PDF wird aus einem anderen digitalen Format wie Microsoft Word oder Excel erstellt. Native PDF-Dateien enthalten eine lesbare und interpretierbare interne Struktur.
C. Woher weiß ich, ob ich eine durchsuchbare PDF-Datei habe?
- Um zu wissen, ob Ihre PDF-Datei durchsuchbar ist, müssen Sie sicherstellen, dass die jeweilige Datei textbasiert ist. Das bedeutet, dass es echten Text enthalten muss. Um zu überprüfen, ob Sie eine durchsuchbare PDF-Datei haben oder nicht, müssen Sie sie öffnen und mit Ihrer Tastatur oder Maus einen Text suchen oder auswählen. Wenn Sie keinen Text auswählen oder hervorheben können, bedeutet dies einfach, dass die PDF-Datei nicht durchsuchbar ist.